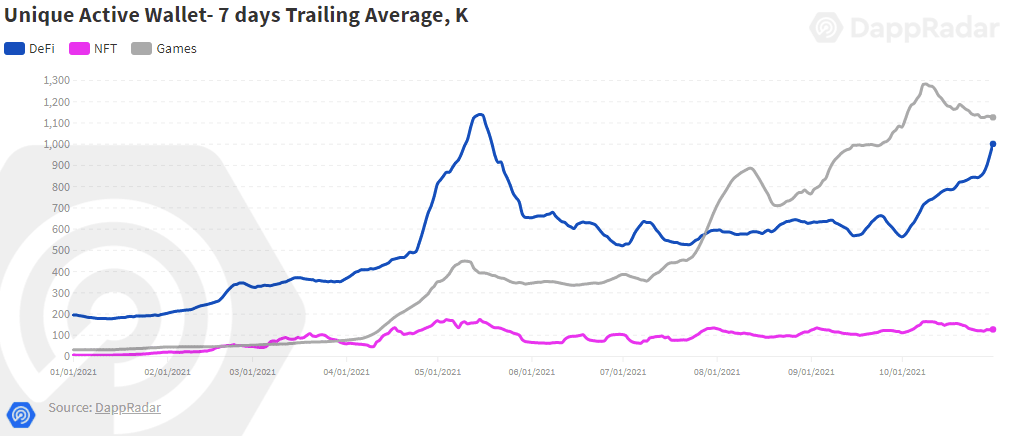
今年链游的数量和玩家人数都有了大规模的增长,
来自DappRadar的一份报告显示,
10月份平均每天有超过100万个独立的活跃钱包地址连接到链游app中,
而资本市场当月更有1.2亿美金投入链游相关的平台项目中。
一方是玩家大量的涌入链游,另一方则是链游项目在资本的助推下不断涌现。
这时候连接的价值日益显现:
比如YGG等公会的出现,连接了游戏和玩家两方,
通过游戏道具的租借和专业的培训,
使玩家进场成本更低收益更高,也使游戏方获得了更多的用户。
而当游戏越来越多,单一公会其实无法带领玩家触达每一个链游,
各类公会就出现分而治之的局面,各自招募玩家奔向不同的链游。
这时候,就出现了一种平台的机会,
能够连接所有的玩家,链游和不同的游戏公会,
给它们一个互相发现、互相匹配并获取收益的渠道。
今天我们要讲的GuildFi就是这样一个平台,
专注于与玩家、游戏和公会之间的连接。

GuildFi是什么
弥补链游市场需求和现实的差距
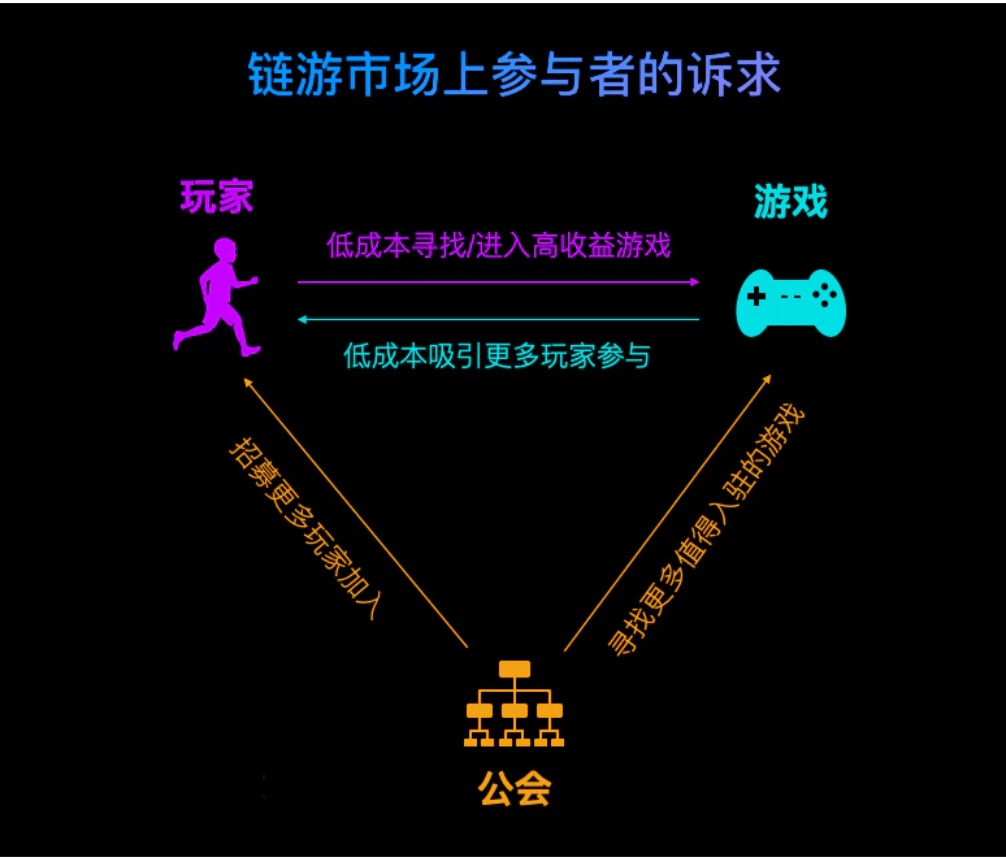
在介绍GuildFi之前,我们不妨先看看目前链游市场上的参与者和他们的需求。
- 玩家:需要低成本的寻找+进入更多收益高的游戏,并把游戏中投入的时间价值最大化;
- 游戏:需要低成本且广泛的吸引玩家参与;
- 公会:需要快速创建公会并招募玩家参与,并需要找到更多值得入驻的游戏。
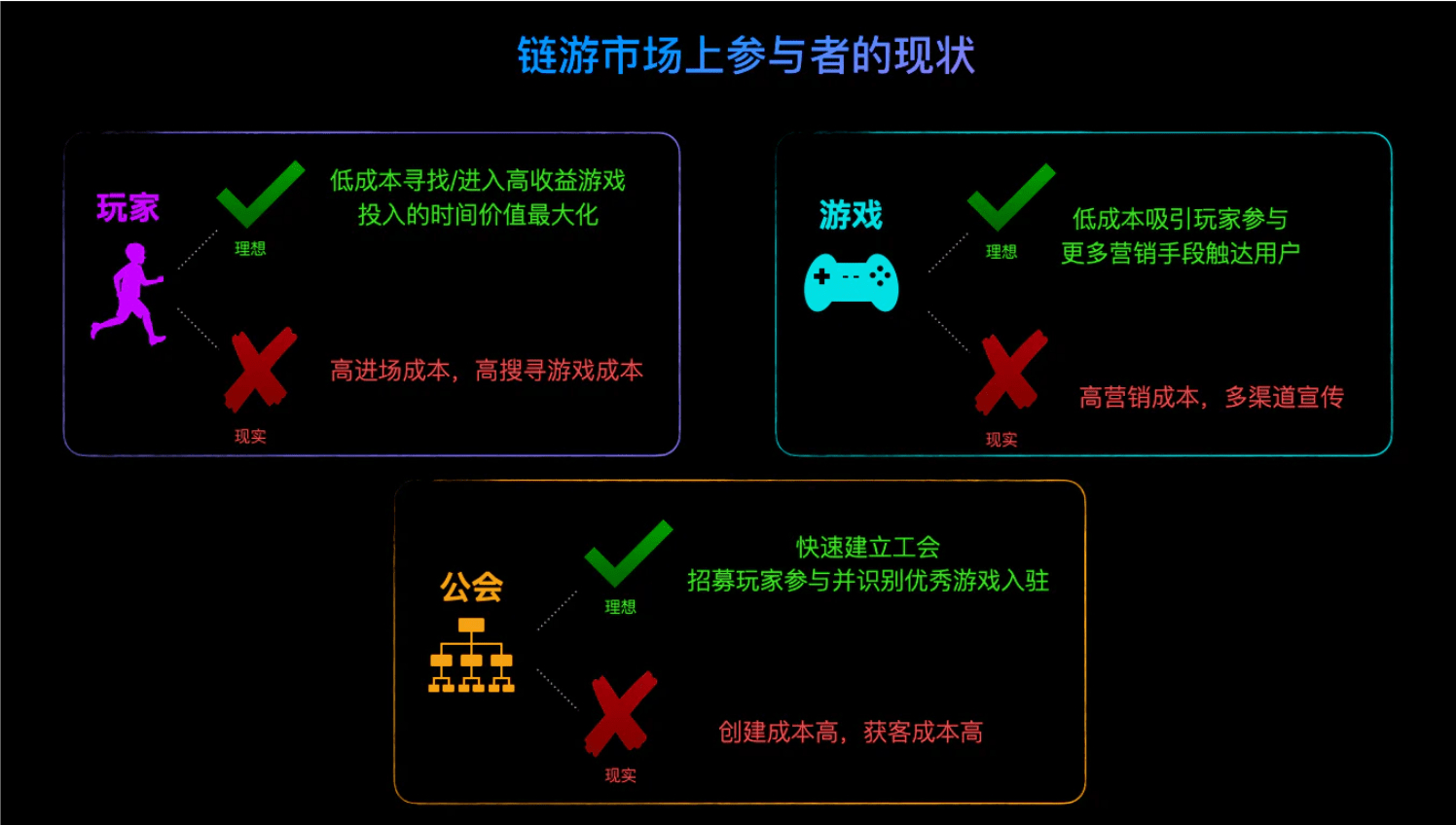
而在目前的链游市场中,现实情况并不能完全满足他们的需求:
- 玩家:零散的寻找要进入的游戏,支付高额进场费用,研究打金攻略,投入产出比不稳定;
- 游戏:多渠道通过广告、运营活动和社交媒体进行营销和获客,存在投放宣传成本;
- 公会:各自创建公会并找寻玩家,创建公会需要大量启动资金,且寻找玩家成本高
可以明显的看出,三类角色的需求和现实情况仍存在着差距,
因此目前的链游市场其实可以构建一个平台来连接玩家、游戏和公会,
并解决他们在现实情况中遇到的问题。
GuildFi: 连接链游市场各参与方的多功能服务平台
GuildFi的目标是努力缩小现在链游市场上各参与者的需求和现实差距,
其实现手段则是为玩家、游戏和公会提供各自急缺的服务,
并作为一个平台将服务资源在三者之间共享,以达到相互发现,提升效率的目的。
总体来看,GuildFi提供了四大服务:游戏平台、公会专区、NFT专区、工具专区,
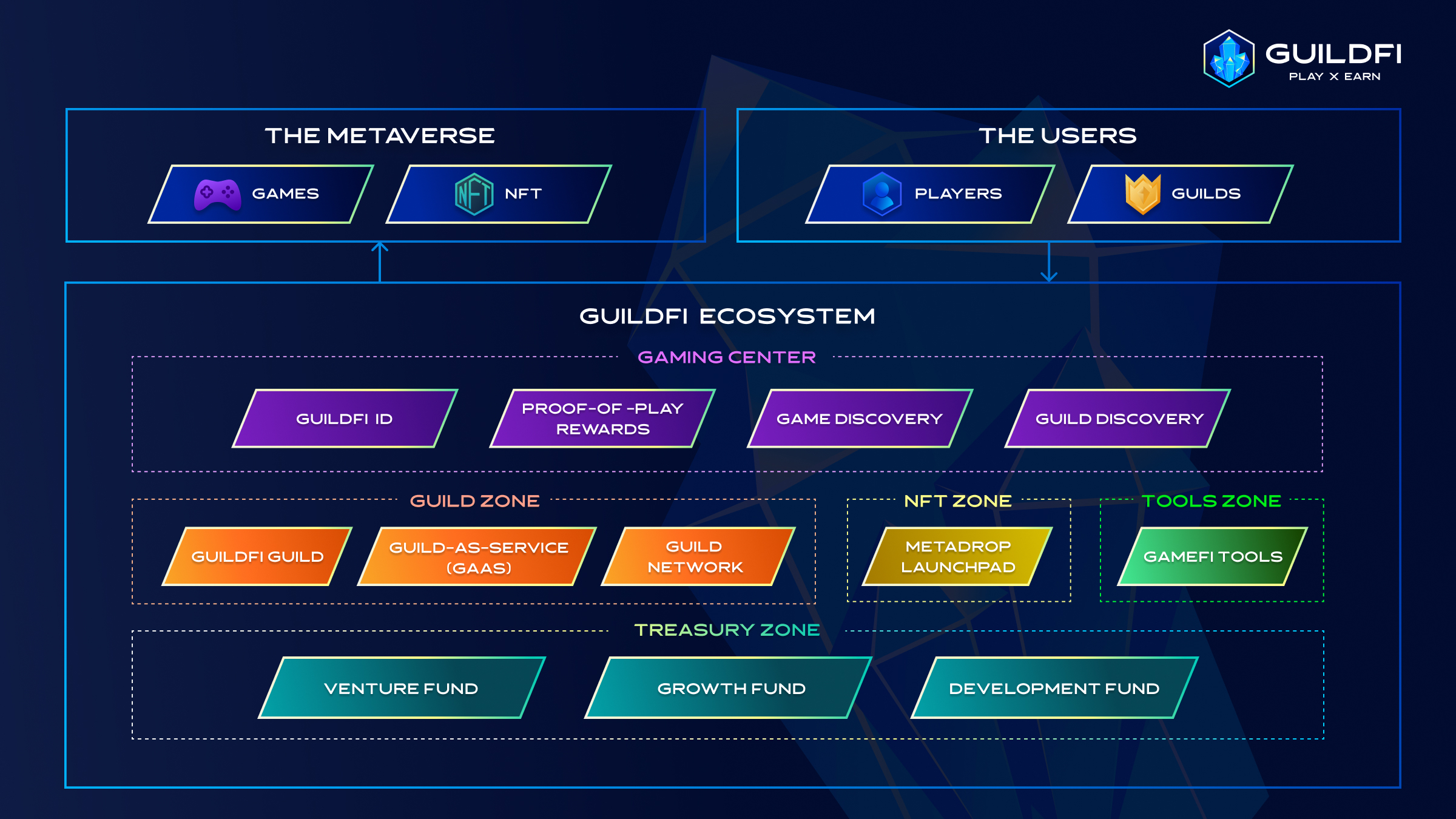
每一个服务中又细分成了不同的功能模块。
考虑到GuildFi中的模块较多,单纯的介绍功能未必能完全理解它的设计用意,
我们仍然接着上面玩家、游戏和公会各自遇到的问题来讲解GuildFi的功能设计,
看看它是如何对症下药来解决问题的。
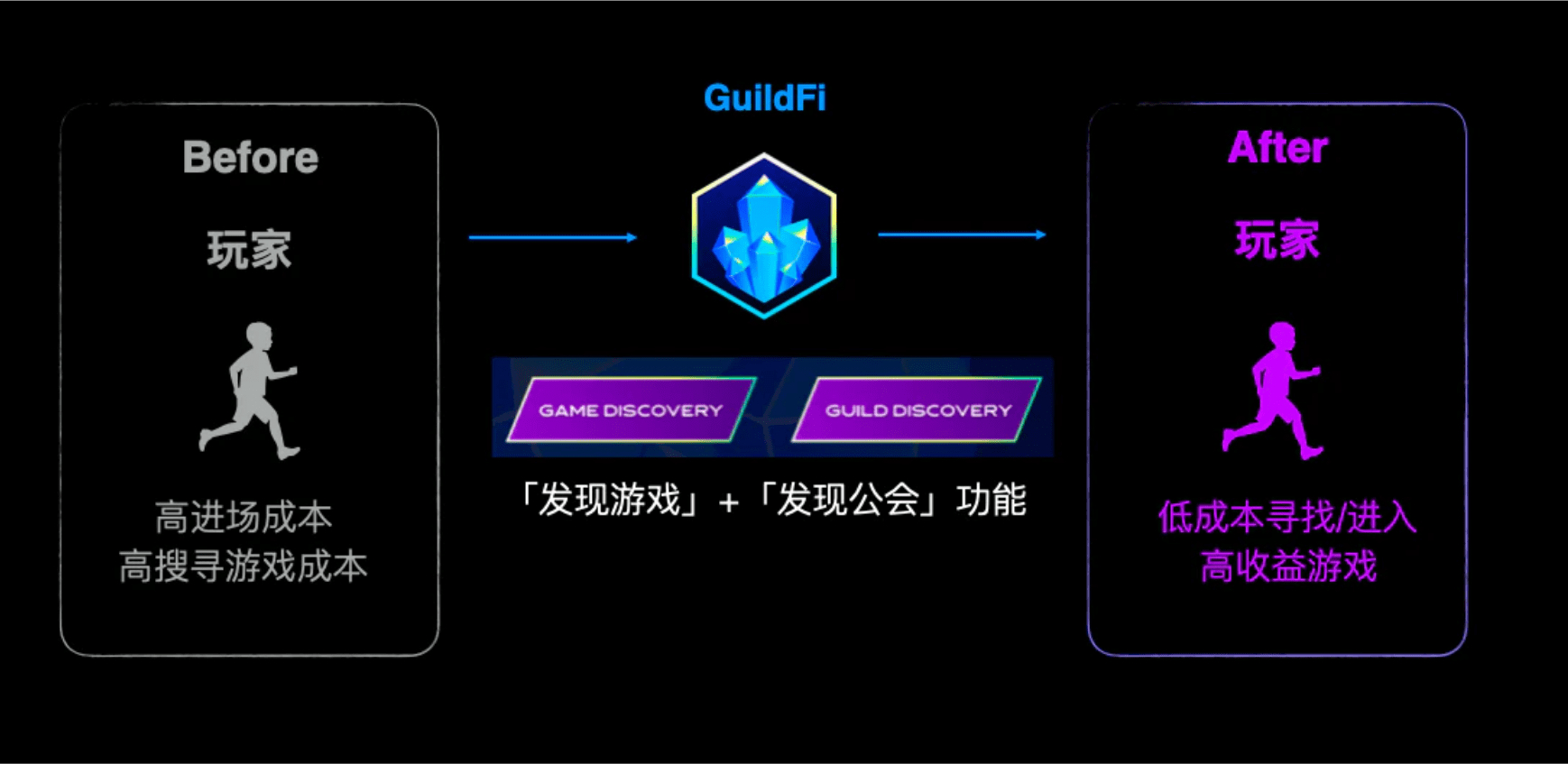
1.玩家:通过「发现游戏」和「发现公会」功能,降低游戏寻找成本和进场成本
在GuildFi的游戏平台功能中,有2个叫做发现「游戏发现」和「发现公会」的功能。
在游戏发现方面:
即平台会列出目前值得参与的游戏列表,
并提供该游戏的基础信息和相关的数据分析。
对于数据分析功能,目前官网显示功能即将上线,
但我们可以猜测,这类分析一定与游戏活跃用户数、投入产出比等信息相关,
借此来为玩家提供是否参与游戏的判断依据。
在游戏方面,官网上目前支持的游戏仅有2款,分别是Cyball和Axie,
而在官方的白皮书中我们则看到了另外两款引人关注的作品也将整合进入GuildFi:
Sandbox和Star Atlas。
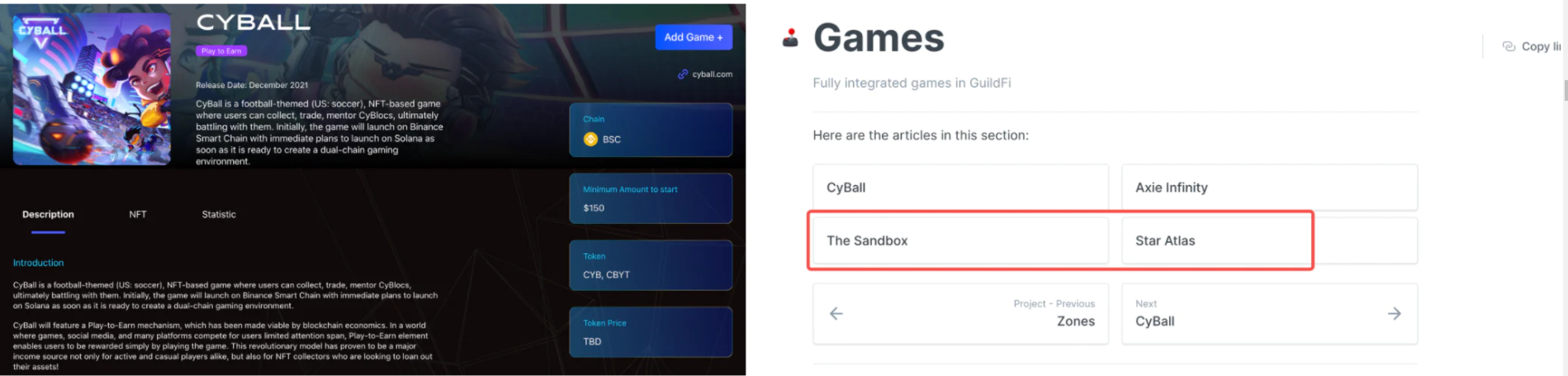
这几款游戏的号召力不必多提,前期选入游戏发现列表中也是GuildFi吸引用户的举措,
但能够争取到这几款游戏加入,足见GuildFi在链游领域的资源。
对于另外一个名为「公会发现」的功能,其实不难理解,
当链游市场上有很多公会时,玩家可能不知道加入其中的哪一个,
而GuildFi也提供了公会列表,并列出了不同公会的所在区域和与用户分成的比例。
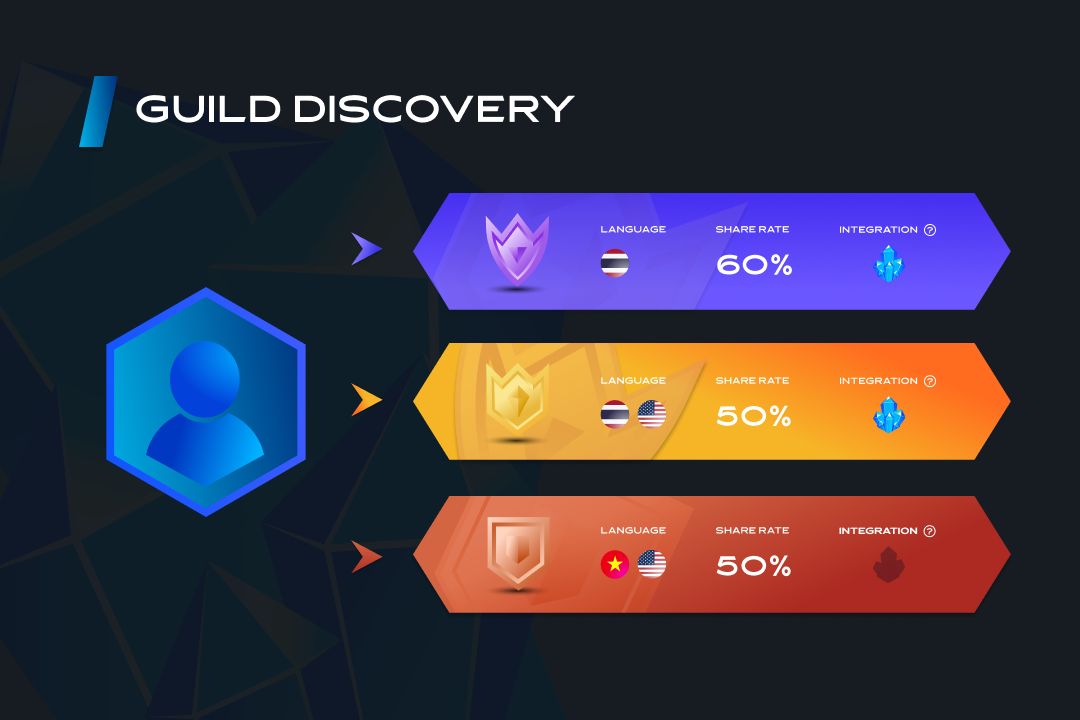
此外最重要的是,公会往往会提供“奖学金”计划,
通过租赁游戏进场所需的NFT,降低玩家进入游戏的成本,
并提供专业的辅导和教学来告诉玩家如何提高打金水平和收益。
这些信息若都能集成在GuildFi中,将极大程度的降低玩家的学习成本和进场成本,
这就解决了前文所述的玩家在现实中面临的问题。
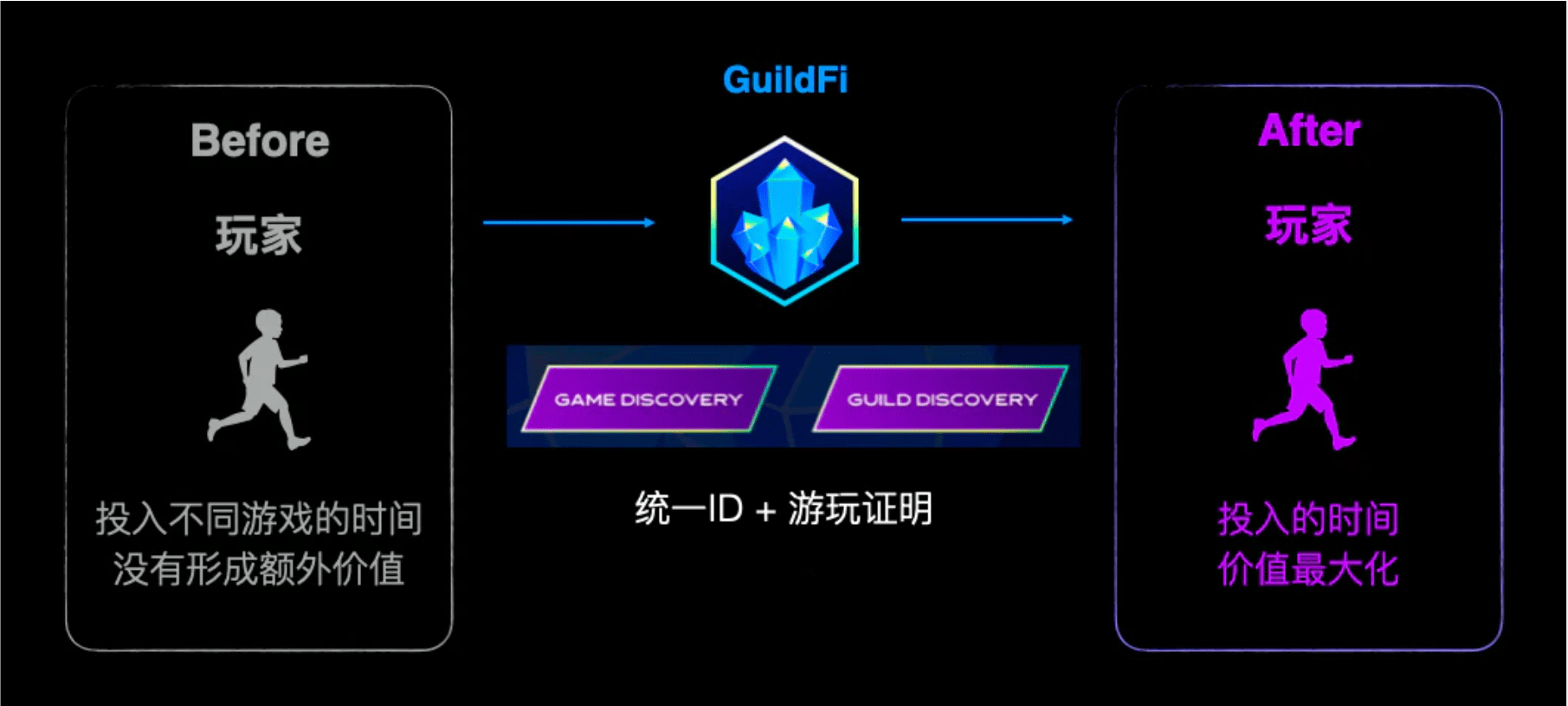
2.玩家:通过一站式账号ID和经验值系统,最大化玩家的时间价值
在游戏平台中还存在两个功能分别是GuildFi ID和“游玩证明”,
前者是该平台的通用ID,仅需简单的注册步骤,
即可达到“一个账号,畅玩平台全部游戏”的效果,而不同游戏的时长,成就等也都集成在账号中,
这非常类似苹果商店或者谷歌商店的账号,能够管理手机内所有下载游戏的信息。
而与ID关联的则是任务和奖励系统,平台会自动关联你玩的所有游戏,
并设计一系列的任务让你达成,成功后可以获得GXP(GuildFi的游戏经验值系统),
这些奖励可以让你获得额外的NFT空投,新游戏提前体验以及GF通证。
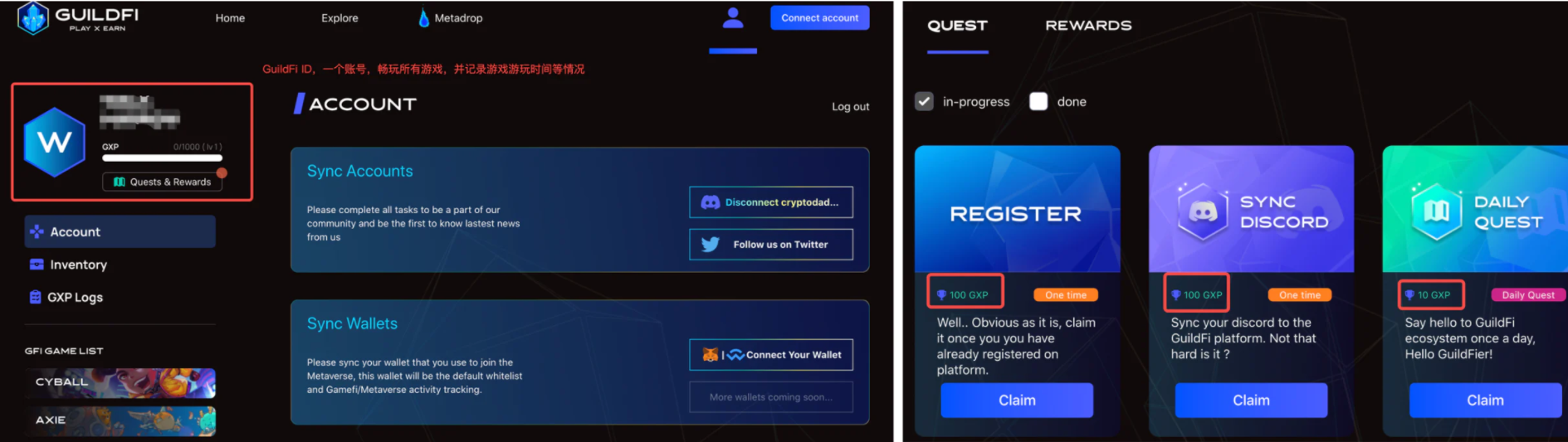
这种统一账户ID和游戏经验值奖励的设计,则最大化了玩家投入时间的价值,
而以前玩家玩不同的游戏仅能获得游戏内的奖励,
现在则多了一层GuildFi平台提供的奖励,一举多得。
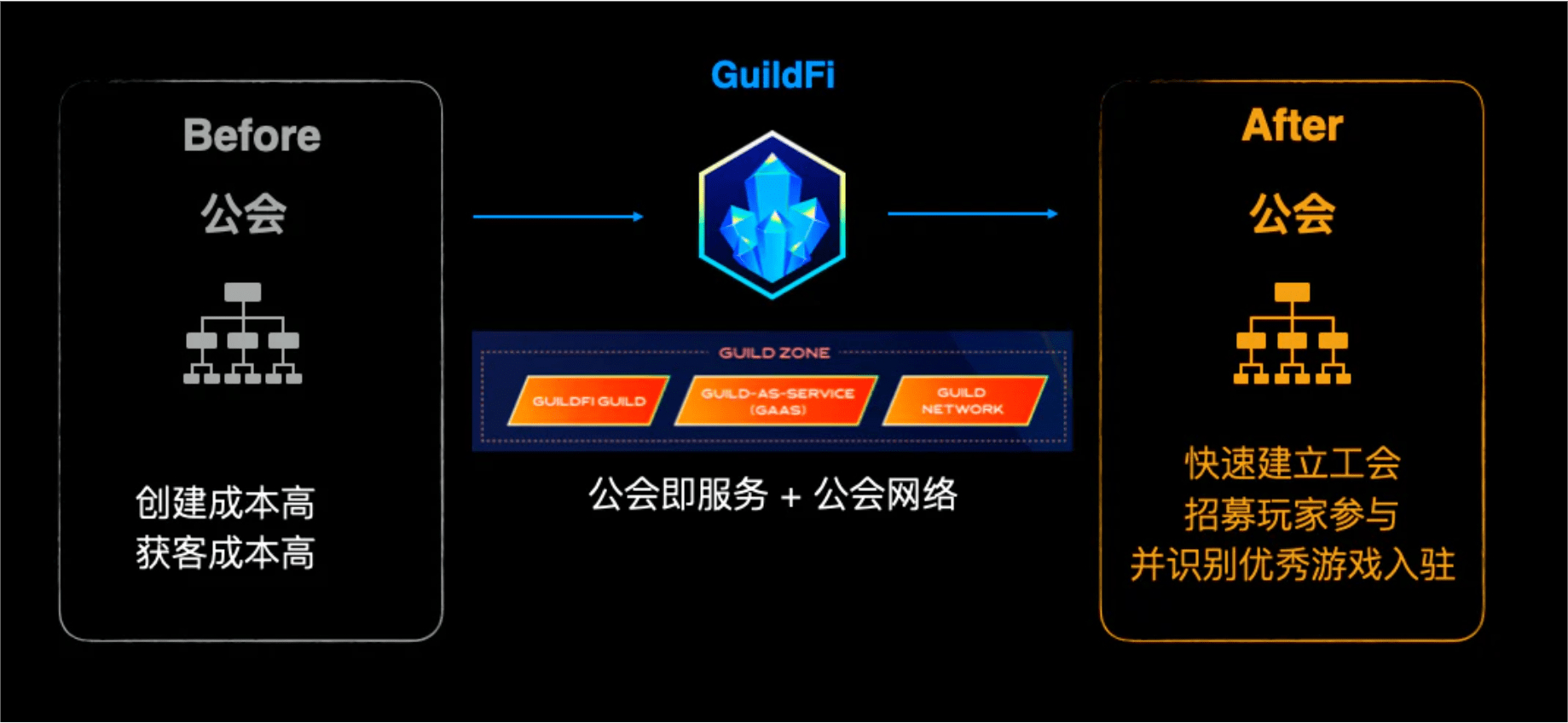
3.公会:提供公会网络+一站式公会组建服务,降低公会组建和运营成本
GuildFi作为一个平台,自然会有自己的基金和天使投资,
通过背后资金的支持,初始创建的公会可以向平台借入NFT资产,
而公会则可以将这些资产再借出给招募的玩家,这就降低了公会的资金成本。
此外,如果多个公会都入驻了GuildFi平台,他们之间也可以互相出借NFT资产,
这也达到了公会间资源的优化配置。
在招募玩家方面,GuildFi也内置了一个“奖学金门户”,
使公会能够更为快捷的通过平台招募到玩家,这也对应着前文介绍的面向玩家的“公会发现”,
达到了玩家和公会之间匹配效率的提升。
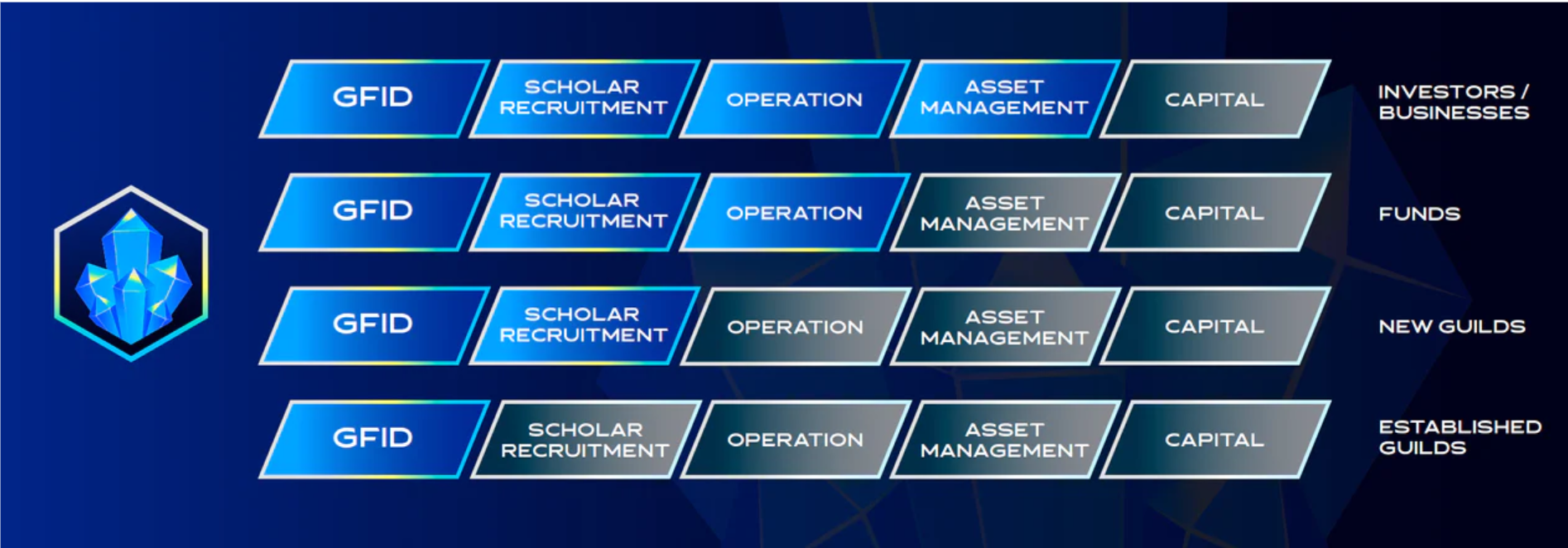
更为重要的是,GuildFi平台推出了一项“公会即服务”的功能,
这个概念与时下流行的“云服务”和“软件即服务”的概念类似,
即由GuildFi提供各种公会所需要的模块,如创建ID、注资、运营、资产管理等,
公会进来可以按照自己目前发展的阶段,按需选取相应的模块和服务,从而完善自己的公会建设。
而以上这些则解决了公会目前在链游领域面临的种种问题。
4.游戏:Metadrop作为营销手段吸引更多用户参与
对于玩家来说,吸引他们参与某个游戏的理由,
除了打金收益外,不定时的NFT和通证空投也是其中之一。
对玩家来说的“薅羊毛”,其实对游戏方来说则是一种重要的获客手段。
GuildFi平台也提供了一个Metadrop专区,专供游戏方来发布空投,
而玩家则依据前文所述的GXP等来获得不同层级的空投奖励,
此举也更好的连接了玩家和游戏方,而这种直接的激励都可以在同一个平台上完成,
在平台粘性增加的同时,接入平台的游戏方均可受益。
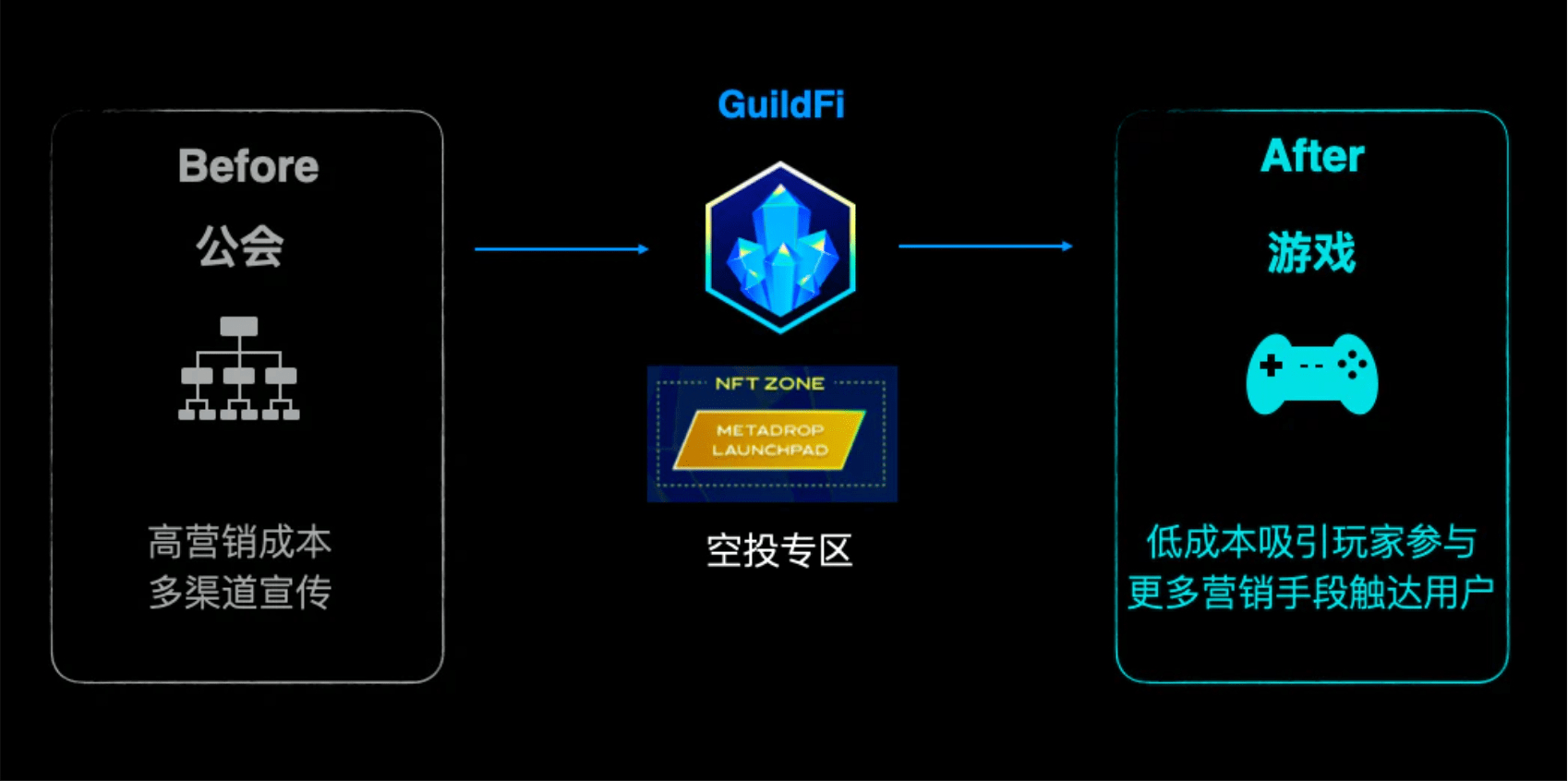
最后,游戏的工具专区在官网中并没有得到体现,
白皮书中描述该区域主要是用于公会奖学金的账户管理和支付管理,
同时还能看到不同游戏的排行榜以及PVP模拟等,
这一部分内容是GuildFi基于Axie的公会经验所开发的,
实际成品功能的普适性有待后续观察。
GuildFi的基本面:优秀资方加持+丰富的公会经验
GuildFi已经完成了600万美元的种子轮融资,
除了Definance和hashed领投之外,
Aniomca,coinbase及coin98等也参与了投资,
这些知名的资方入局,也体现了资本对于构建GuildFi平台的看好,
毕竟目前市场上公会众多,而连接公会游戏和玩家的平台则没有出现龙头。

而关于GuildFi,其前身也是一个泰国本地的游戏公会,
成立社区超过5年,并活跃在Axie、THG和传奇4等游戏中,
举办过不少公会活动,如举办杯赛和组织团队击杀游戏BOSS等。

这些公会经验在建立GuildFi平台时可以得到复用,并指导其他公会的创建和运营。
GF通证介绍
在了解完GuildFi的全部功能后,其通证GF的作用就变得非常易于理解,
随着GuildFi的功能落地和发展,GF对GuildFi的功能存在价值捕获的效应:
- 价值发现:GuildFi里的游戏玩家越多,游戏生态越庞大,则意味着平台收入的提高和流量的增加,这将对GF通证形成利好。
- GF DAO会员权益:持有GF,玩家可以抢先体验游戏,参与稀有NFT分配和空投,并获得质押奖励。此外,GuildFi为公会提供的各种创建服务也会产生收益,玩家可以依据持有的GF比例获得不同额度的分成。
- 治理与决策:投票哪些游戏可以加入GuildFi等。
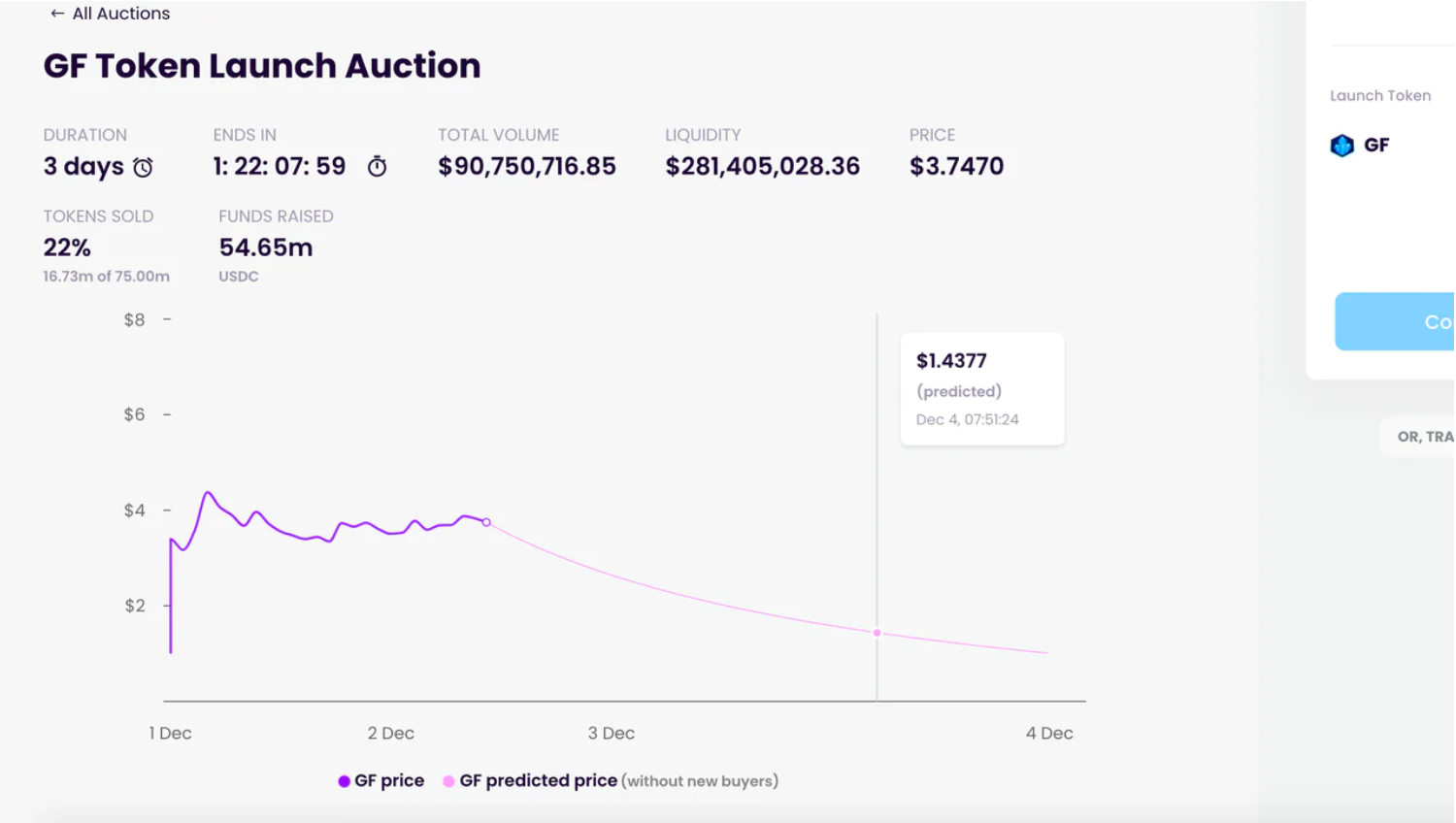
值得一提的是,GF目前正在官方进行通证拍卖。
起始时间为12月1日-12月4日,并采用价高者得的荷兰拍卖形式, 有兴趣的读者可以关注。
GuildFi的潜力和风险
综合来看,GuildFi目前在做的是典型的平台建设,
即通过平台来匹配市场上的供需方,实现资源最优配置。
这种做法类似于滴滴打车平台, 通过吸引打车人和车主入驻,且无论车辆属于哪家服务公司, 都能满足运输能力和出行需求的高效匹配。
这里的打车人=玩家,这辆车=游戏, 车主或者服务公司=公会,而滴滴=GuildFi。
而平台经济往往具备两个优势, 即“赢家通吃”和“先发制人”,
一旦用户粘性构建起来后, 其他想要效仿该平台则难以获得同级别的流量。
也正因为GuildFi在做连接玩家、游戏和公会间的平台,
它的定位和我们熟知的YGG也是不一样的,
GuildFi可以被理解为: YGG + 公会搭建支持 + 公会资源贡献 + 平台经济。
但我们也应该清楚的认识到,
做一个连接的平台也不存在技术壁垒,
其他的公会也可以争相模仿,如果竞对拥有更快的建设速度和更加雄厚的资本支持,
那么GuildFi的优势也有可能被瓦解。
此外,一些优质的链游出于利益的考虑可能也不会选择和平台合作,
类似著名手游元神不和发行渠道合作,独自负责宣发而避免高额的抽成,
这时候GuildFi的连接游戏方的作用也会受到影响。
而无论如何,一个完整的元宇宙概念里,
游戏,玩家和公会应该是可以高效的相互链接的,
在目前元宇宙中的角色们还处在一个个孤岛中的情况下,
构建连接是完全值得提倡的。
虽然连接不同角色的道路比较难走,
涉及到各类资源的整合,
但最曲折的路有时最简捷,
这条路可能也是通向元宇宙繁荣的捷径。